今日進度6/14:
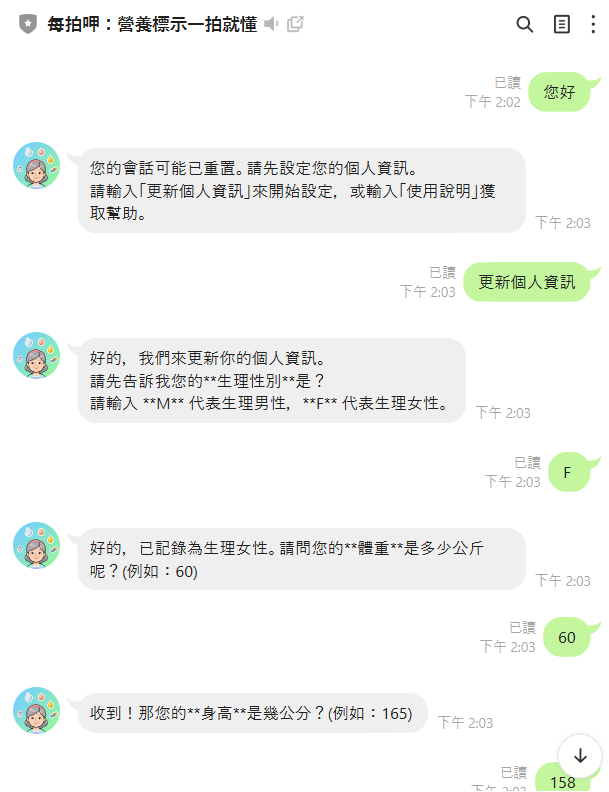
針對「簡化用戶輸入個人資訊的步驟,目前要請用戶自己用逗號隔開(女性, 60, 158 1),這樣對用戶來說不太方便。」。
建議解方:採用「對話式分步引導」。
與其讓用戶一次輸入所有資訊,不如將其拆解成多個簡單的問題,讓用戶只需一步一步回答,大大降低輸入門檻。
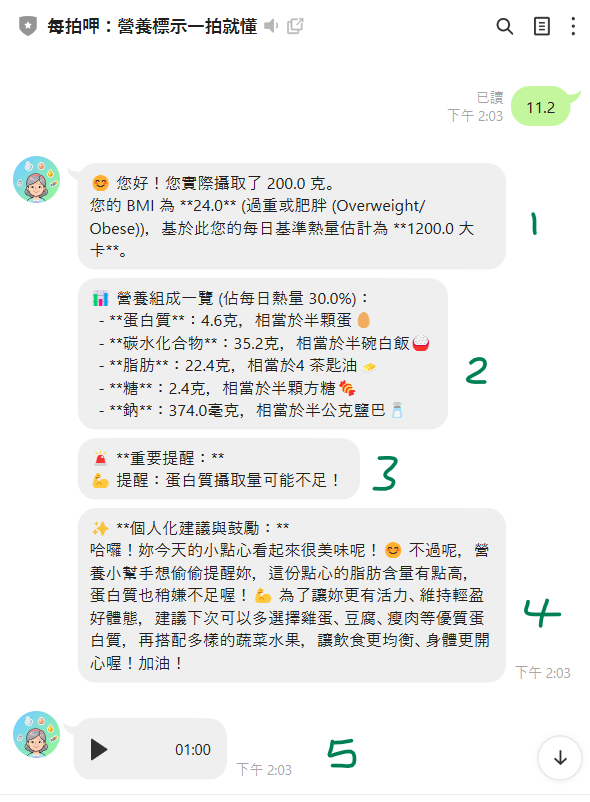
針對改善文字報告可讀性 (多個對話泡泡)
問題點: 目前所有分析結果都集中在一個 LINE 對話泡泡中,文字量大,長輩閱讀起來會感到擁擠和吃力。
建議解方:拆分成「多個邏輯清晰的對話泡泡」。
LINE Bot 支援一次傳送多個訊息物件。我們可以將冗長的報告拆分成幾個短小精悍的區塊,每個區塊一個對話泡泡。
不過,這一part在測試的時候出問題了😫
我看後台顯示分析和語音都已生成,但用戶並未收到,研究了一下發現,原來原因是 LINE Messaging API 的單次推播訊息數量限制,導致用戶端未能收到最終報告:「messages ensure this value has at most 5 items」,這表示單次的 PushMessageRequest 最多只能包含 5 個訊息物件。目前的程式碼在生成報告時,總共建立了 5 個 TextMessage 泡泡,加上一個 AudioMessage,總計 6 個訊息,超出了LINE API的限制。
為了解決這個問題,將原先的「總結與問候」和「個人健康概覽」這兩個文字泡泡合併成一個,總數改為4個,這樣加上語音訊息,總數就不會超過5個了。
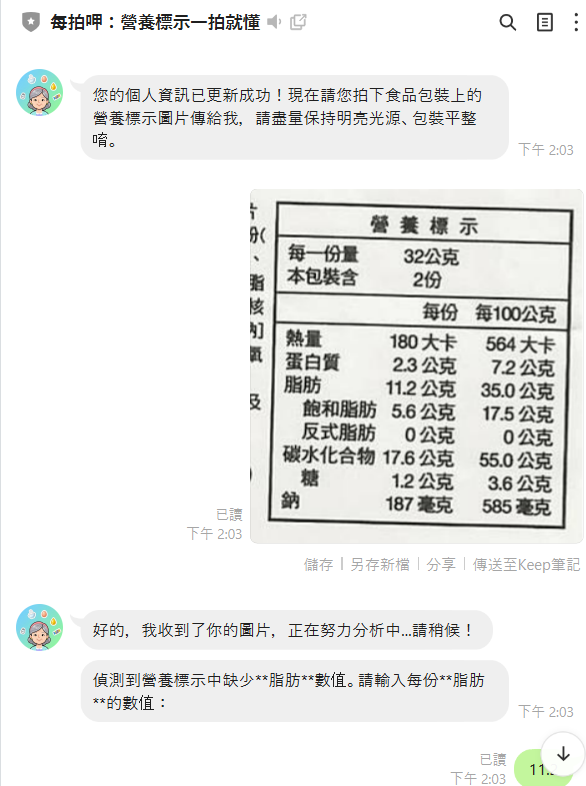
辨識錯誤問題 (手動輸入缺失部分)
問題點: 當照片因皺褶、反光等因素導致部分營養標示辨識失敗時,用戶目前只能重新上傳照片,無法手動修正。
建議解方:加入「手動補齊缺失資訊」的互動流程。
用戶手動輸入:
用戶透過文字訊息輸入缺失的數值。
重新分析: Bot 收到用戶輸入後,將缺失的數據補齊,然後重新進行營養分析並產生報告。
範例流程:
用戶傳送圖片。
Bot (LINE): 「我收到了!分析中...」
OCR 辨識發現「脂肪」數值缺失。
Bot (LINE): 「偵測到您的營養標示中缺少脂肪資訊,請問每份脂肪是幾克呢?」
用戶 (LINE): 12.5
Bot (LINE): 「好的,已補齊脂肪資訊,正在重新分析中...」
Bot 成功生成完整報告。
[目前的LINE BOT互動長這樣](https://youtube.com/shorts/7YHRXVugGyA?feature=share
明日進度:
因為提前做完很多天的進度,所以問Gemini有沒有優化建議,我覺得這些都很棒耶!
接下來就看看能解決多少囉!
Gem的優化建議
增強 OCR 辨識準確性:
目前的 OCR 邏輯是基於通用模型和關鍵字搜尋。你可以考慮進一步優化 parse_nutrition_from_ocr 函數。例如,可以實作更智能的表格結構解析,或是利用更多圖片預處理技術(如裁剪、銳化營養標示區域),讓辨識結果更精確,減少手動輸入的需求。數據持久化與用戶歷史記錄:
目前用戶的個人資訊和分析數據在程式重啟後會遺失。你可以導入一個輕量級資料庫(例如 SQLite 或更專業的 Firestore),來儲存用戶的生理性別、體重、身高和過往的營養分析報告。這樣不僅能提供用戶查詢歷史記錄的功能,也能讓 Bot 在每次互動時有更完整的用戶上下文,提供更一致的體驗。更豐富的 LINE 訊息呈現:
雖然多泡泡訊息已經很棒了,但 LINE 提供了強大的 Flex Message (彈性訊息) 功能。你可以嘗試將營養分析報告以更視覺化、更具互動性的方式呈現,例如條狀圖顯示各營養素佔比、點擊展開詳細資訊等,這會讓報告看起來更專業也更吸引人。個人化建議的深度與廣度:
Gemini AI 已經提供了很棒的建議。未來可以思考如何讓建議更「智慧」:考慮用戶的飲食偏好:例如,如果用戶是素食者,Bot 可以推薦植物性蛋白質來源。
長期飲食趨勢分析:如果能追蹤用戶多筆紀錄,Bot 可以分析其長期飲食習慣,並給出基於趨勢的建議(例如:「您最近糖分攝取偏高,建議多選擇無糖飲品。」)。


 iThome鐵人賽
iThome鐵人賽